Plateforme E2E - Extension du Projet Final (v2)
Cette page documente l’extension du projet final DE2 : une plateforme End-to-End temps réel ajoutée par-dessus le pipeline Spark Medallion noté. Le rapport noté (Rapport Final) couvre l’architecture Batch Spark + Streaming + PageRank + LLM-readiness. Cette page-ci décrit ce qu’on a construit en plus : Kafka, Airflow, un backend API et un dashboard web temps réel, le tout orchestré sous Docker Compose.
1. Vision et motivation
Le pipeline noté lisait les fichiers GH Archive en mode batch (spark.read.json("data/archive/*.json.gz")). C’est efficace pour l’évaluation, mais peu réaliste : en prod, les données arrivent en continu, pas par lots horaires figés. L’extension v2 répond à cette limite en branchant une architecture event-driven complète :
- Un producer qui rejoue les events GH Archive dans un topic Kafka (simule l’arrivée temps réel).
- Spark Structured Streaming qui consomme Kafka 24h/24 et écrit la couche Bronze.
- Airflow qui orchestre les jobs batch Silver/Gold à intervalles réguliers.
- Une API FastAPI qui expose les agrégations Gold via REST.
- Un dashboard Next.js qui consomme l’API et rafraîchit toutes les 30 s.
Le tout reste reproductible localement via un seul docker-compose up -d.
2. Architecture End-to-End
┌──────────────┐ ┌──────────┐ ┌──────────────┐ ┌──────────┐ ┌──────────┐
│ GH Archive │──▶│ Producer │──▶│ Kafka topic │──▶│ Spark │──▶│ Bronze │
│ (.json.gz) │ │ (Python) │ │ raw.events │ │ Streaming│ │ Parquet │
└──────────────┘ └──────────┘ └──────────────┘ └──────────┘ └────┬─────┘
│
┌──────────┐ ┌──────────┐ ┌────────────────┘
│ Frontend │◀──│ FastAPI │◀──│ Gold / Silver
│ Next.js │ │ + DuckDB│ │ (Airflow DAG)
└──────────┘ └──────────┘ └────────────────┘
Lecture de bas en haut : les events bruts entrent par GitHub Archive, transitent par Kafka, sont stockés en Bronze par Spark Streaming, puis raffinés en Silver et Gold par des DAG Airflow programmés. Le backend FastAPI interroge la couche Gold via DuckDB (in-process) et l’expose à un dashboard web qui rafraîchit en continu.
3. Composants de la stack
| Service | Image / Tech | Rôle | Port |
|---|---|---|---|
| Zookeeper | confluentinc/cp-zookeeper:7.5 | Coordination Kafka | 2181 |
| Kafka | confluentinc/cp-kafka:7.5 | Bus streaming (topic github.raw.events) | 9092 (host), 29092 (interne) |
| Kafka UI | provectuslabs/kafka-ui | Console de visualisation des topics | 8090 |
| Producer | Python 3.10 custom | Rejoue .json.gz GH Archive → Kafka | — |
| Spark Bronze | PySpark 4.0 + Structured Streaming | Consume Kafka → écrit Parquet bruts 24/7 | — |
| Airflow Webserver | Apache Airflow 2 | UI orchestration | 8080 |
| Airflow Scheduler | Apache Airflow 2 | Déclenche les DAG Silver/Gold | — |
| Airflow Metadata | Postgres 13 | Stocke les états des DAG | — |
| Backend | FastAPI + DuckDB | API REST analytics | 8000 |
| Frontend | Next.js 16 + Tailwind v4 | Dashboard temps réel | 3000 |
Total : 10 services orchestrés via un seul docker-compose.yml.
4. Stack technique étendue
Streaming & Orchestration
- Apache Kafka 7.5 (Confluent) — partitioning, consumer groups, exactly-once semantics
- Spark Structured Streaming — connecteur Kafka, micro-batching, checkpointing
- Apache Airflow 2 — DAG, scheduler, executor
LocalExecutor, Postgres metadata DB
Serving & API
- FastAPI (Python async) — API REST, schémas Pydantic, Swagger auto à
/docs - DuckDB — SQL analytique in-process, lit directement les parquets sans serveur intermédiaire
Frontend
- Next.js 16 + Turbopack — framework React avec hot-reload
- Tailwind CSS v4 + Framer Motion + Recharts — design system, animations, graphiques
- lucide-react — bibliothèque d’icônes
Conteneurisation & Sécurité
- Docker Compose — orchestration locale, 10 services interconnectés
.env+.env.example— externalisation des credentials, jamais hardcodés- GitHub Actions CI — build Quartz + gitleaks + CodeQL sur chaque PR
- Branch protection sur
main(PR + CI green required)
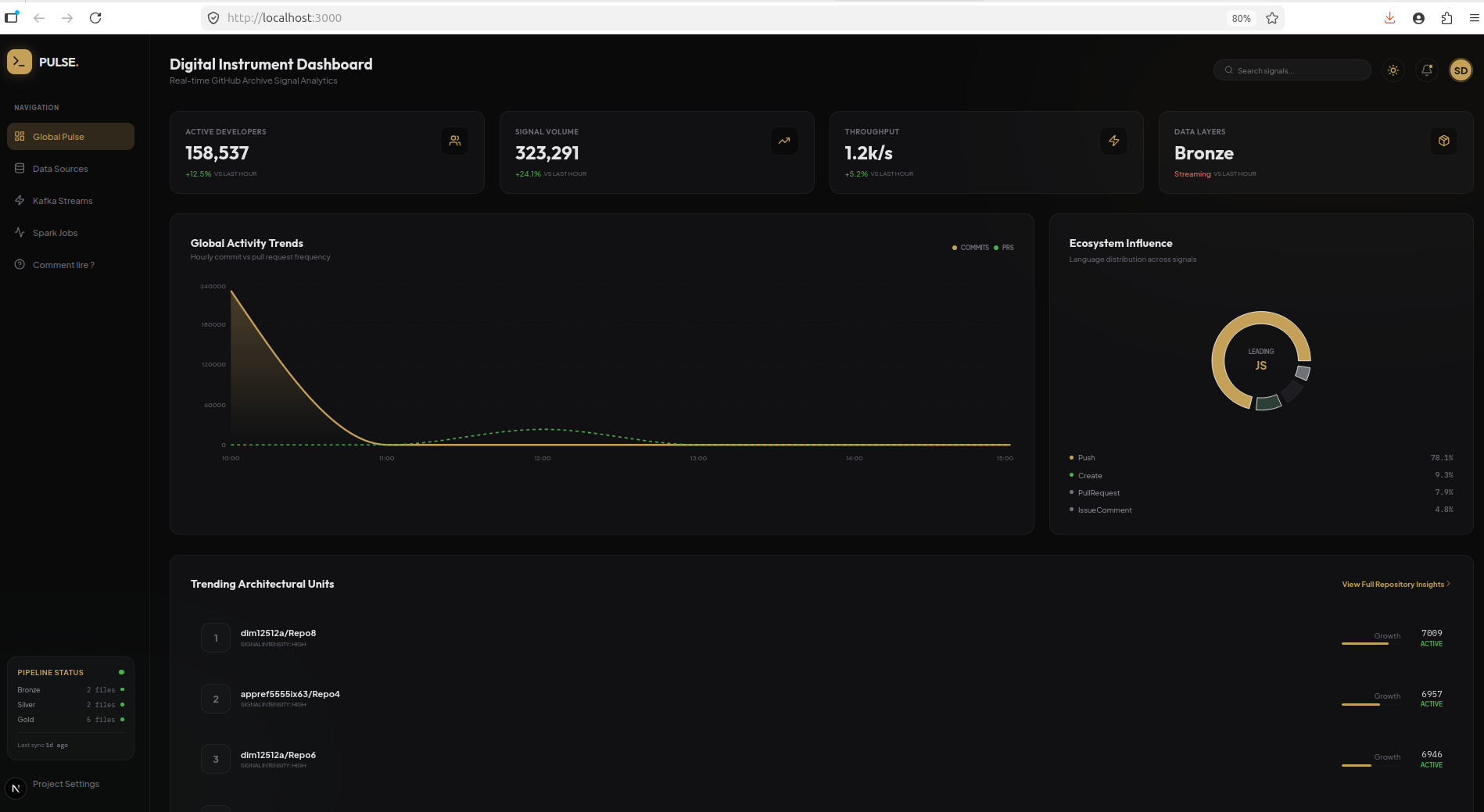
5. Le dashboard “Luxe de Minuit”
Le dashboard implémente une esthétique cinématique inspirée des design systems premium (Dribbble). Tout est interactif et rafraîchi automatiquement.
Mode sombre (par défaut)
Mode clair (palette Aurore)
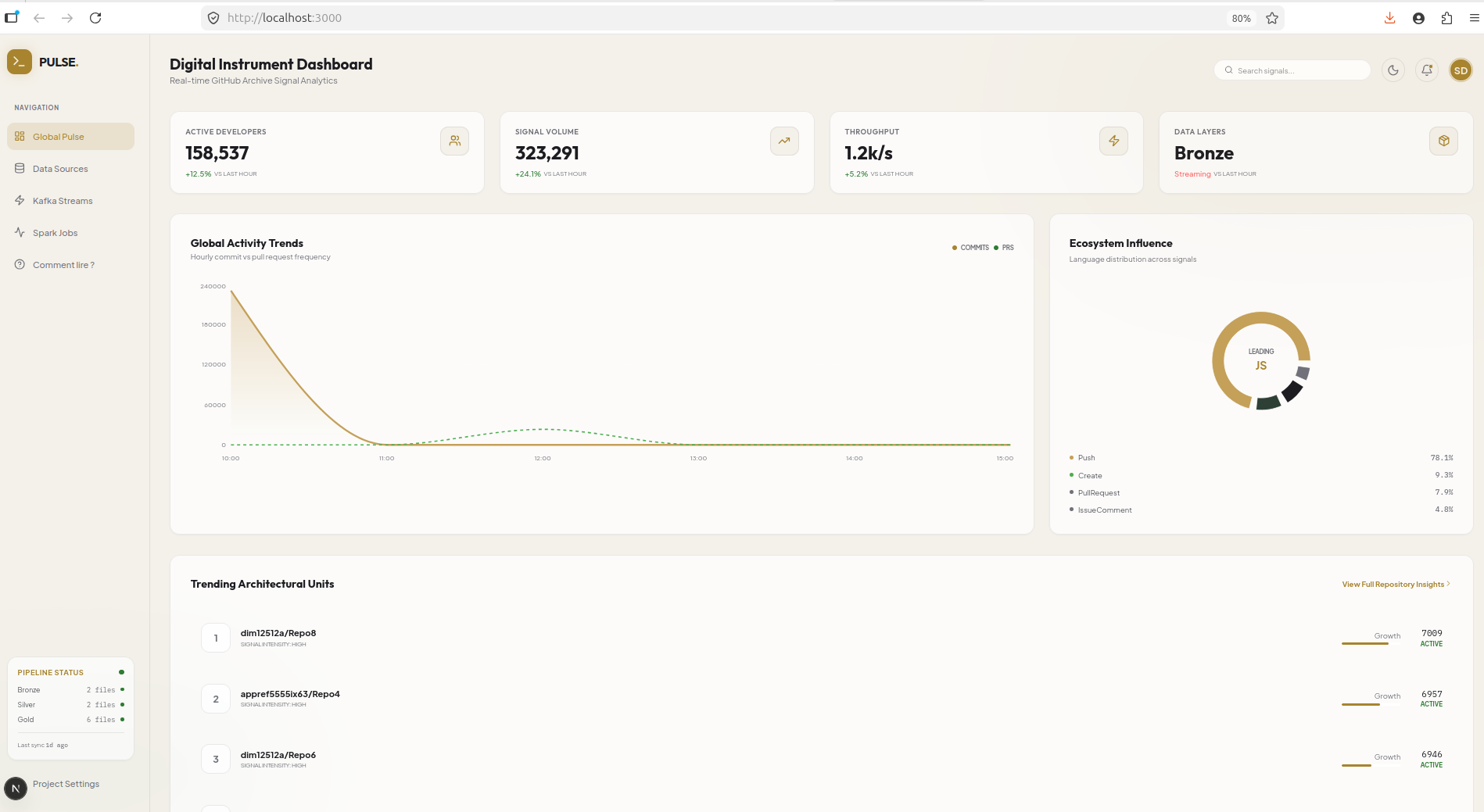
Le toggle dans le header permute en 0.4 s entre les deux modes via une classe theme-light sur le <body> qui réécrit les variables CSS --color-* définies dans @theme Tailwind v4. Les graphiques Recharts, les animations Framer, et tous les composants suivent automatiquement.
Composants visibles
- 4 KPI temps réel :
Active Developers(158 537 calculé en direct depuis la couche Bronze),Signal Volume(323 291 events Gold agrégés),Throughput,Data Layers(Bronze actif). - Global Activity Trends : courbe
commits(or) vspull requests(vert pointillé). - Ecosystem Influence : pie chart donut de la distribution des
event_type(Push 78.1 %, Create 9.3 %, PullRequest 7.9 %, IssueComment 4.8 %). - Trending Architectural Units : top dépôts par activité.
- Pipeline Status (sidebar bas-gauche) : panneau live qui scanne le filesystem et compte les parquets Bronze/Silver/Gold + horodatage du dernier sync.
- 5 vues sidebar : Global Pulse, Data Sources, Kafka Streams, Spark Jobs, Comment lire ? (guide pédagogique intégré pour les non-techniques).
6. Calcul du KPI “Active Developers”
Pour compter les développeurs uniques, le backend exécute une requête DuckDB directement sur la couche Bronze streaming (pas de pré-agrégation Gold requise) :
SELECT COUNT(DISTINCT actor_login)
FROM read_parquet('bronze_v2/**/*.parquet', union_by_name = true)
WHERE actor_login IS NOT NULLRésultat actuel : 158 537 développeurs uniques sur 1 510 316 events ingérés.
7. Lancer la plateforme localement
git clone https://github.com/samba-diallo/website-quartz-data-engireering.git
cd "website-quartz-data-engireering/Data Engineering 2/project final"
cp .env.example .env # éditer les valeurs <change_me>
docker-compose up -dAccès une fois la stack démarrée :
| Service | URL |
|---|---|
| Dashboard | http://localhost:3000 |
| Backend API + Swagger | http://localhost:8000/docs |
| Airflow UI | http://localhost:8080 |
| Kafka UI | http://localhost:8090 |
Guide complet (prérequis, vérifications, troubleshooting, arrêt propre) : documentation/PIPELINE_RUNBOOK.md dans le repository.
8. Choix techniques notables
- DuckDB plutôt que Postgres côté backend : SQL analytique in-process, zéro serveur à maintenir, lit directement les parquets Gold produits par Spark. Latence < 100 ms.
- Medallion file-based plutôt que Delta Lake / Iceberg : suffit pour un projet pédagogique single-node, sans dépendance à un metastore.
- Producer Python custom plutôt que Debezium / Kafka Connect : plus simple à comprendre et adapté au cas “rejouer un fichier
.json.gz”. LocalExecutorAirflow plutôt queCeleryExecutor: pas besoin de workers distribués sur une machine locale, plus rapide à démarrer.- Hot-reload Next.js via volume sync : permet d’itérer sur le design sans rebuild Docker à chaque modif (gain temps massif pendant le développement).
9. Sécurité
Une revue de sécurité complète a été menée avant publication GitHub :
- Credentials externalisés dans
.env(gitignored), template documenté dans.env.example. - GitHub Secret scanning + Push protection activés sur le repo.
- gitleaks intégré à la CI (scan secrets sur chaque PR).
- CodeQL (Python, JS/TS, Actions) tourne automatiquement.
- Branch protection sur
main: PR obligatoire, CI verte requise, force-push bloqué. - Dependabot alerts + security updates activés.
10. Suite et améliorations
- Déploiement public : Vercel pour le frontend Next.js + Railway/HuggingFace Spaces pour le backend FastAPI conteneurisé.
- Job Gold
user_activity: agrégeractor_logincôté Spark Gold pour éviter la requête DuckDB sur Bronze à chaque appel API. - Vrai graphe temporel : remplacer le bricolage horaire actuel par un
GROUP BY date_trunc('hour', event_timestamp)côté Spark Silver/Gold. - Refactor monorepo : organiser le code en
apps/+services/+archive/pour la lisibilité long terme.
Code source
Toute la stack est sur GitHub : samba-diallo/website-quartz-data-engireering, branche v2-kafka-airflow.
Document rédigé en mai 2026, en complément du rapport noté.